
نرم افزار Squid تعداد زیادی از روشهای ذخیرهسازی صفحات یا فایلهای کششده را ارائه میدهد. این روشها شامل کش در حافظه استاندارد و روشهای دیگری است که در نهایت همگی آنها به ذخیره در دیسک میانجامند. پاسخهای کششده در مخازن مشتری ذخیره میشوند و به تاریخچه آنها در حافظه یا روی دیسک اختصاص دارد. زمانی که باید بازیابی شوند، خوانده میشوند و پاسخ کششده به مشتری درخواستکننده ارسال میشود.
معمولاً Squid با استفاده از 4096 بایت حافظه بافر، هدرهای پاسخ را مدیریت میکند. این بدان معناست که هر پاسخی که هدرهای آن بیش از 4096 بایت باشد، از چندین بافر که به یکدیگر افزوده شده تشکیل میشود. اما هنگامی که یک پاسخ در دیسک ذخیره شده و سپس بهدنبال آن بازیابی میشود، Squid بهدرستی با پاسخهای ذخیرهشده که به چندین بافر 4096 بایتی مرتبط هستند، برخورد نمیکند.
مسأله اصلی در تابع `store_client::readBody` وجود دارد که مسئول تحلیل پاسخ از دیسک است. این مساله زمانی اتفاق میافتد که offset برابر با صفر است و len بیشتر از صفر است و rep وضعیت پاسخ هنگام sline برابر با Http::scNone است:
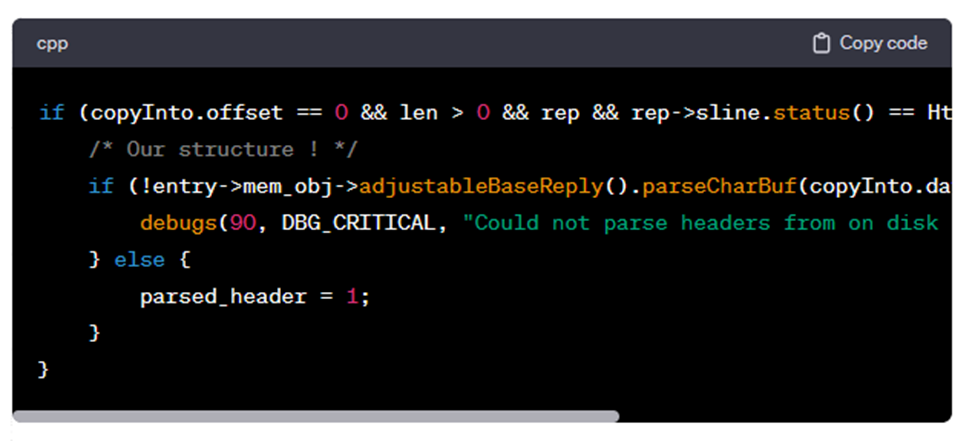
در واقع ایراد اساسی مربوط به کد زیر میباشد:
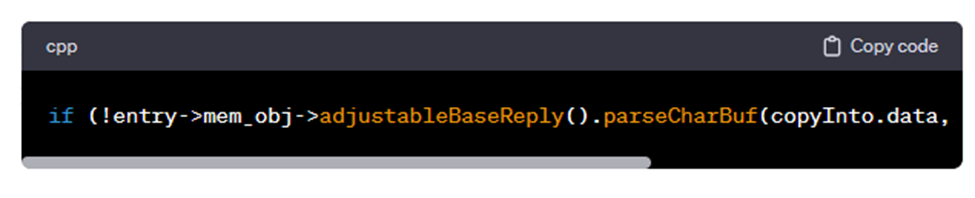
تابع `headersEnd` برای تعیین اینکه هدرها در درخواست کجا به پایان میرسند و بدنه اصلی درخواست، (اگر مربوط باشد) از کجا شروع میشود، استفاده میشود. اگر `headersEnd` یک درخواست نامعتبر را دریافت کند، صفر را بهعنوان خطا برمیگرداند. درحالیکه پاسخهای STORE_OK بهطور عادی بدون بررسیهای دیگر به `headersEnd` منتقل میشوند. در خصوص پاسخهای ذخیره شده، داده به 4096 بایت کوتاه میشود و بنابراین بیشتر پاسخهای ذخیره شده با هدرهای بیشتر از 4096 بایت خراب میشوند. وقتی تابع `parseCharBuf` با طول صفر فراخوانی میشود، یک خطا رخ میدهد و هدرها بهصورت تجزیهنشده علامتگذاری نمیشوند و در نهایت Squid متوجه میشود که مشکلی وجود دارد و یک صفحه خطای «500 خطای داخلی سرویس» به مشتری درخواستکننده ارسال میکند. بدنه این صفحه خطا حاوی پاسخ ذخیره شده بهصورت کامل (شامل هدر و بدنه) و بدون فیلتر میباشد.
این مسئله به دلایل مختلفی مشکلساز است:
1. بهراحتی میتوان یک صفحه ایجاد کرد تا با هدرهای بزرگ پاسخ ارسال کند، آنگاه در دیسک ذخیره و کش شود. اما تأثیر این کار کم است، زیرا تنها شیء کش شدهای که ممکن است خراب شود، یک صفحه است که از پیش کنترل میشود.
2. میتوان یک صفحه را که بر آن کنترل نداریم، به پاسخ با هدرهای بزرگ ترغیب کنیم. یکی از روشهای ممکن میتواند آسیبپذیری Host Header Injection باشد که تقریباً در همه جا امکانپذیر است. روشهای دیگر هم وجود دارند برای مثال: response splitting
3. پاسخ خطایی که Squid به مشتری ارسال میکند، بدون فیلتر و برچسب است و همان چیزی را که در هدر پاسخ بوده است و در بدنه وجود دارد، ارسال میکند. این بدان معناست که هر پاسخی که هدرهایش حاوی HTML باشند، بهعنوان HTML تجزیه میشود. در شرایطی که ما میتوانیم هدرهای پاسخ یک صفحه وب را کنترل کنیم، اجرای جاوااسکریپت در مرورگر بهسادگی امکانپذیر است؛ زیرا این هدرها اکنون بهعنوان بخشی از بدنه در نظر گرفته میشوند.
برای مثال، فرض کنید یک 'هدف' داریم که هدرهای (پاسخ) را ارسال میکند:
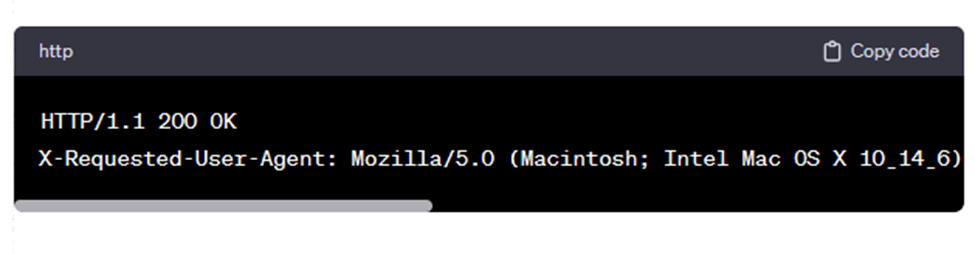
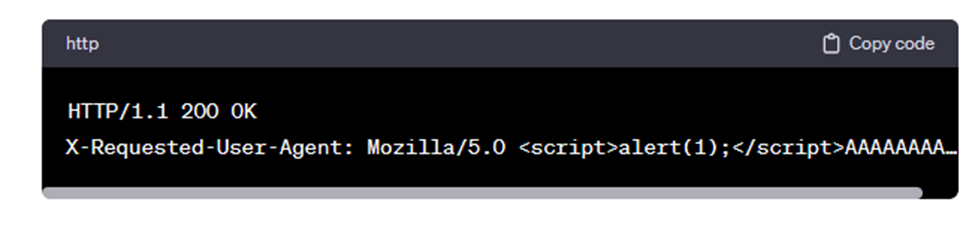
اگر این حروف A باعث شوند که هدرهای پاسخ بیش از 4096 بایت شوند، هنگامی که پاسخ روی دیسک ذخیره میشود، پاسخ قابل بازیابی نخواهد بود. بازدیدهای بعدی از همان صفحه باعث میشود که پاسخ کامل (یعنی هدر و بدنه) به شرح زیر باشد:
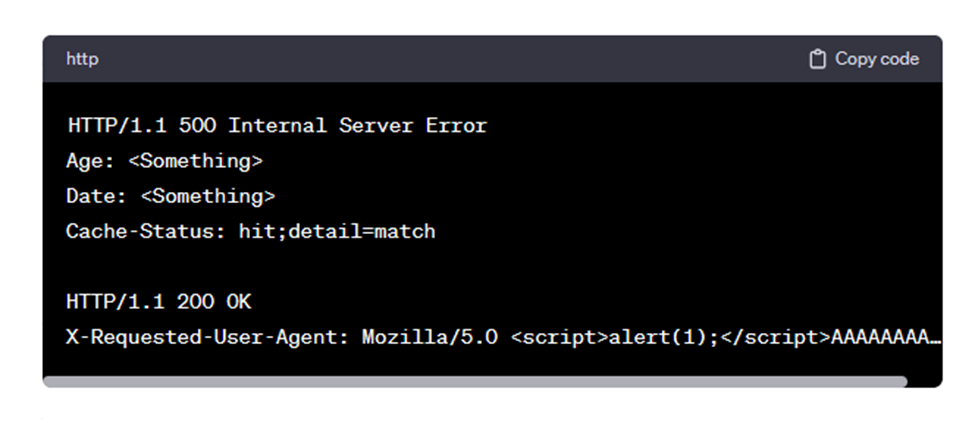
بنابراین، هدرهای اصلی پاسخ در بدنه پاسخ قرار داده میشوند و سپس میتوانند توسط مرورگر اجرا شوند.
توصیههای امنیتی
جهت جلوگیری از مخاطرات احتمالی آسیبپذیری مذکور میتوانید از راهکارهای امنیتی زیر استفاده کنید:
1. اصلاح کد در Squid: بررسی و اصلاح تابع `store_client::readBody` به منظور افزایش توانایی Squid در مدیریت پاسخهای با هدرهای بزرگتر از 4096 بایت.
2. محدود کردن اندازه هدرها: اعمال سیاست محدودیت اندازه برای هدرهای پاسخ به منظور جلوگیری از ایجاد هدرهایی که بیش از حد بزرگ میباشند.
3. فیلترسازی هدرها: افزودن یک لایه فیلترسازی برای هدرهای پاسخ تا محتوای مخرب یا ناخواسته را حذف یا اصلاح کند.
4. اعمال بهروزرسانی
5. مدیریت دسترسی: افزایش کنترل دسترسی به Squid تا فقط افراد مورد اعتماد اجازه دسترسی به سیستم را داشته باشند.
6. مانیتورینگ و لاگگیری: راهاندازی یک سیستم مانیتورینگ و لاگگیری جهت نظارت بر عملکرد Squid و شناسایی هر نوع فعالیت مشکوک.
7. آزمون امنیتی: اجرای آزمونهای امنیتی دورهای بر روی Squid به منظور شناسایی هرگونه آسیبپذیری جدید.
منابع خبر:
[1] https://megamansec.github.io/Squid-Security-Audit/cache-headers.html
[2] https://github.com/squid-cache/squid/security/advisories/GHSA-wgq4-4cfg-c4x3
- 80